AI Giriş Bölüm 2 | Makine Öğrenmesi
Yapay Zakaya Giriş Ders Notları
Bu yazımız BTK Yapay Zeka'ya giriş ders notlarindan oluşmatadır.
Giriş
Bu bölümde öğrenim nedir, nasıl gerçekleşir, genel kavramlar ve geleneksel programlama arasındaki farklara değinilecek.
Öğrenme Süreci
Bir makine öğrenimi algoritması, matematiksel işlemlerin parametrelerine bağlı olan ağırlık değerlerinin optimize edilme sürecine bağlı olarak öğrenme gerçekliştirdiği süreçtir. Bu süreçte bazı sabit kat sayılar, öğrenme oranı (Learning rate) vb. pek çok dış parametreye de sahip olabilirler.
Öğrenmenin en önemli ihtiyacı verilerdir. Makine öğrenimi, bu verileri matemateiksel algoritmaları üzerinden işleyerek gerçekleşir. Burada veri analizi, aykırı veri tespiti kısaca veri de öğrenime girmeden bir süreçten geçirilerek işlem görmelidir.
Yöntemler
Makine öğrenimi üç temel başlıkta inceleyebiliriz:
- Gözetimli Öğrenme (Supervised Learning)
- Gözetimsiz Öğrenme (Unupervised Learning)
- Pekiştirmeli Öğrenme (Reingorcement Learning)
Öncelikle bilmemiz gereken bazı kavramlar vardır. Şimdi bunu inceleyelim.
Kavramlar
Model
Gerçek dünya sürecinin matematiksel temsilidir. Model, veriden öğrenme işlemini gerçekleştirecek bir algoritmadır. Örneğin; KNN, GradientDescent, Decision Tree, Random Forest, Linear Regression vb. algoritmaların veri ile işlenmesinden sonra oluşan paremetrelin optimize sonucuna model denir.
Öznitelik
Veri kümesinin ölçilebilir bir özelliği ya da parametresine denir. Örneğin bir market için müşterilerin potansiyel birlikte alabileceği bir raf sistemi kuracaksınız. Burada her bir kasa fişi bizim verilerimiz olmakta. Fişiin içeriğindeki bebek bezi, ekmek, ıslak mendil, süt ve mama alınmı olsun. Burada tüm ürünler bizim ÖZNİTELİĞİMİZdir (Feature). Veri seti alınan ürünleri işaretler. Örenk bir veri seti öznitelik tablosu.
| Öznitelik -> | Bebek bezi | Mama | Süt | Yumurta | Ekmek | … |
|---|---|---|---|---|---|---|
| F1 | X | X | X | - | X | … |
| F2 | X | X | X | X | X | … |
| F3 | - | - | X | X | - | … |
| F4 | - | X | - | - | X | … |
Burada özniteliklerimiz; Bebek bezi, Mama, Süt, Yumurta, Ekmek… şekilnde oldu. Verilerimiz (Label) ise F1, F2, F3, F4… şeklinde. Veri setimiz ise X Market Fiş veri seti oldu.
Hedef
Hedef (Label) ise X Market Fiş veri setindeki her bir fişdir (F1, F2, F3, …). Eğitim bu verileri tahminlemek üzere oluşturulur.
Eğitim
Eğitim (Training) ise X Market Fiş veri seti üreindeki verileri işleyerek parametrelerin günceleme sürecidir.
Tahmin
Tahmin (Prediction), veri kümesindeki eğitime katılmatan verileri öğrenim sonrasında modele girdi olarak veriliğ doğruluk, keskinlik gibi değerlerin değerllendirildiği işlem sürecidir.
Bu konuları atladıktan sonra şimdi türlerinden bahsedelim.
Türleri
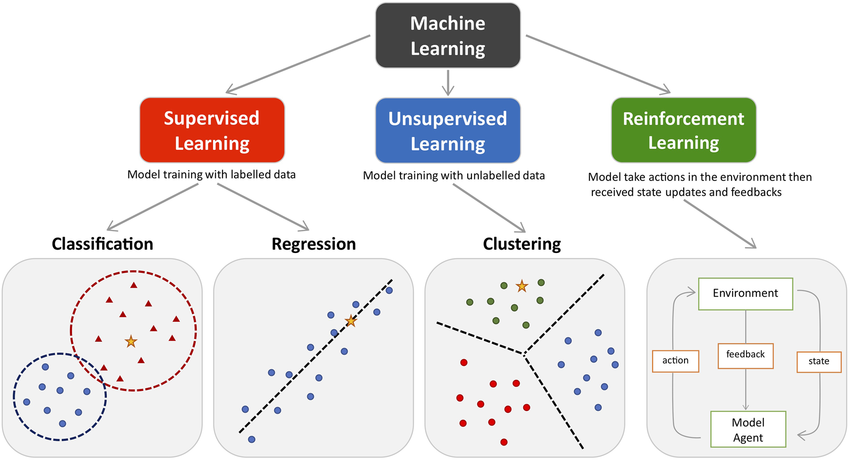
CAPTION Türler 1
Gözetimli Öğrenmede, algoritmaler verideki hedef(label)’lerin doğrultusunda yani, özniteliklere göre ayır edici olan seçeneklere göre eğitilir.
Gözetimsiz Öğrenme ise, yukarıda verdiğimiz örnekteki gibidir. Belirli bir düzeni işleyen ama o işlemlerin bir bağlayıcısı olmayan durumlarda kullanılır.
Daha açıklayıcı bir örnek olamsı için;
| Öznitelik -> | Renk | Ağırlık | UçarMı |
|---|---|---|---|
| Kedi | Siyah | 3 Kg | Hayır |
| Köpek | Siyah | 8 Kg | Hayır |
| Kuş | Gri | 0.2 Kg | Evet |
Bu veri seti Gözetimli öğrenmeye uygun bir veri kümsi örneği olabilir. Yukardaki fiş örneği ise gözetimsiz öğrenim için daha uygun bir veri kümesidir.
Pekiştirmeli öğrenme ise belirli bir veri setine değil(veri seti kullanılmıyor değil) bir simülasyon ortamına bağlı çalışmakta. Çevreden aldığı bilgileri bir ajan yardımı ile işler.
Gözetimli Öğrenme
Eğitim verilerinde girdi ve çıktıyı arasındaki ilikşkiyi öğrenmeye çalışır. Etiketlenmiş bir veri kümesi ile gerçekleştirilen bir yöntemdir. Ana adımları; veri toplama ve hazırlık, model seçimi ve eğitim, model değerlendirmesi, model ayarlanması ve hiperparametre(Learning rate vb. ayarlanabilir parametreleri) optimizasyonu şeklindedir.
Gözetimli öğrenme, sınıflandırma ve regresyon gibi çeşitli problemleri çözmek için kullanılır. Örneğin hastalık teşhisi (sınıflandrıma problemi), müşteri tercihleri tahmin etme, borsa fiyat tahmini (regresyon problemi) gibi problemleri çözer.
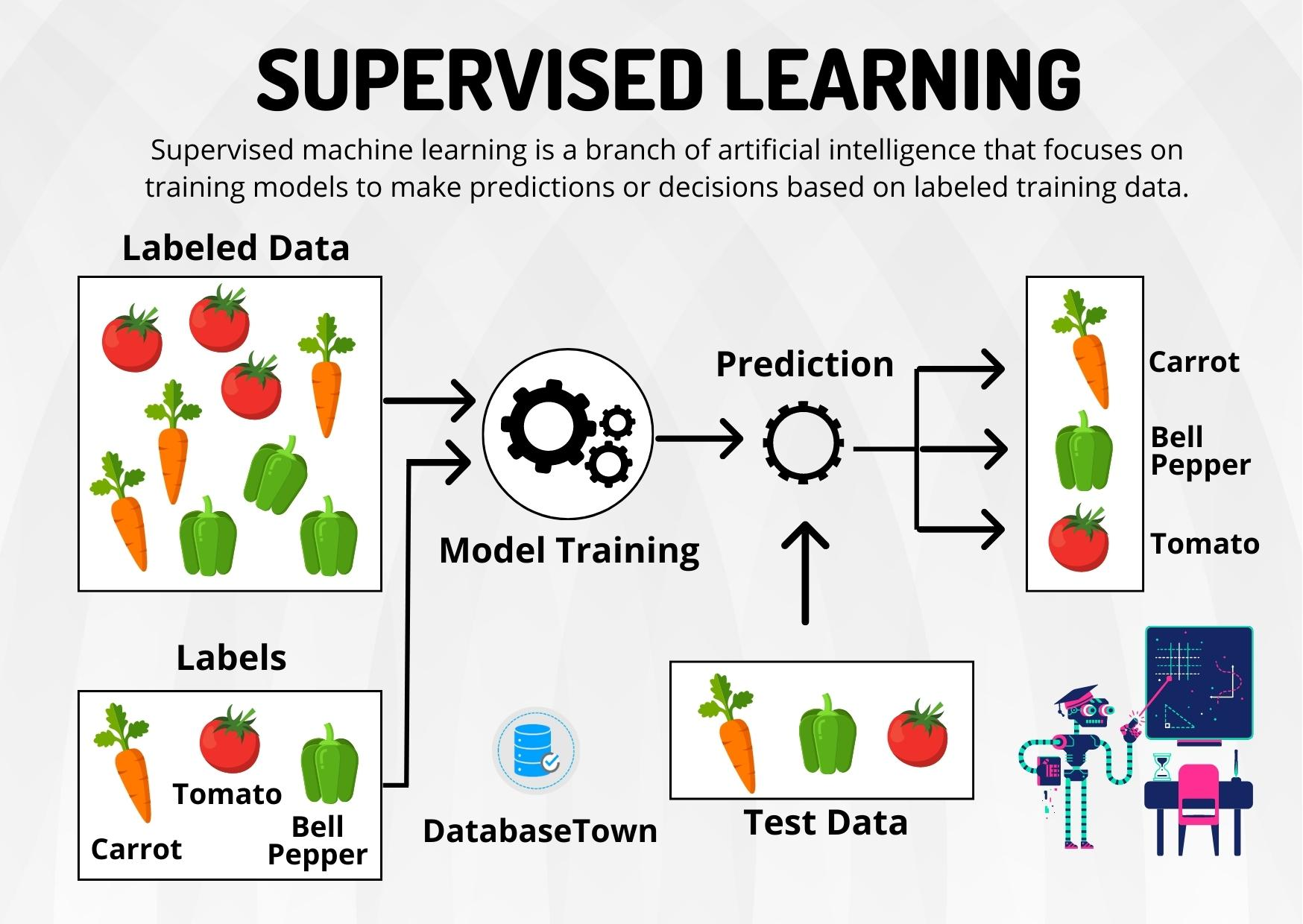
CAPTION Gözetimli Öğrenme 2
Görsel de ifade edildiği gibi veri ler etiketleri ile beraber gelir ve seçilen algoritma ile işlenerek modeli oluşturur. Bu model de eğitim verisinde bulunmayan bir test veri kümesinden veriler ile testedilir ve modelin doğruluğu ölçülür.
Doğrusal Regresyon (Linear Regression)
Doğrusal regresyon, makine öğrenmesinin sürekli çıktı değerlerini tahmin etmek için kullanılan basit ancak etkili bir algoritmadır.
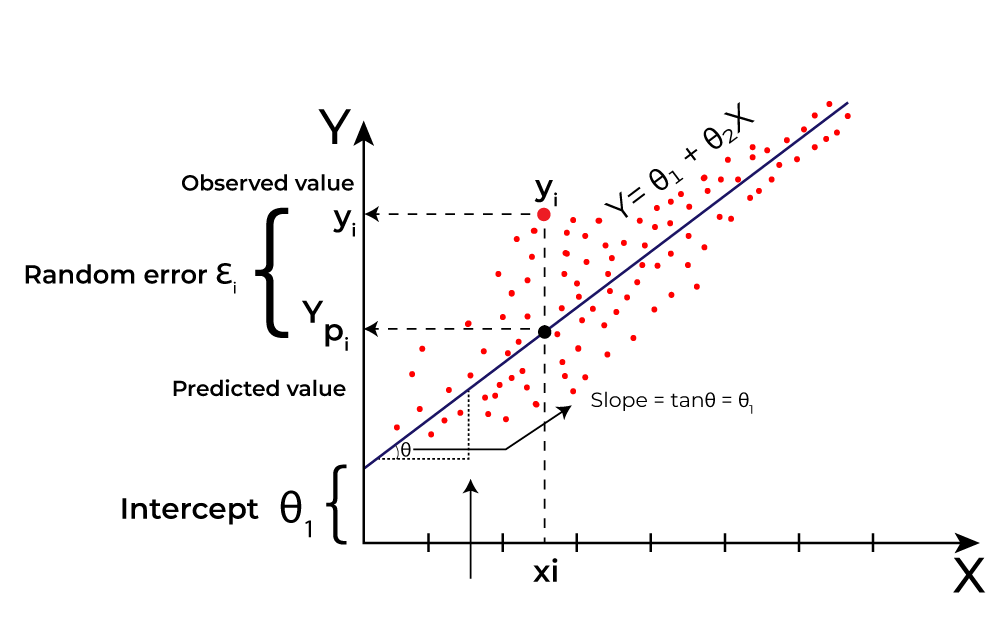
CAPTION Doğrusal Regresyon 3
Görselde görünen X dizleminde bir değeri biliyor ve Y düzemindeki karşılığını arıyorsam kullanabileceğim iyi bir algoritmadır. Temel olarak, giriş özellikleri ile hedef değişken arasındaki doğrusal ilişkiyi modellemeye çalışır. Örnek olarak, ev fiyatları tahmin etme vb. şekilde kurgulanan algoritmalarımızdır.
Lojistik Regresyon (Logistic Regression)
Sınıflandırma problemlerinin çözümü için kullanılır. Temel olarak, giriş özekkikleri ile birlikte bir veri noktasıının bellirli bir kategoriye ait olma olasılığını tahmin eder.
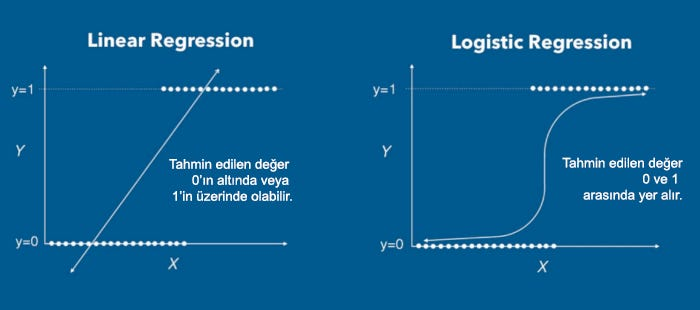
CAPTION Lojistik Regresyon 4
Bir e postanın spam olup olmadığı tahmit etmekte kullanılabilecek bir algoritmadır.
Karar Ağaçları (Decision Tree)
Sınıflandırma ve Regresyon problemlerini çözmekte kullanılan algoritmadır. Veri kümesindeki özelliklerin değerlernine göre bir dizi karar düğümü oluşturulark veriyi sınıflandırır veya regresyon yapar. Çeşitli türleri vardır; rastgele ormanlar (random forests) ve gradient boosting modelleri karar ağaçlarının performansını artırmak için kullanılan popüler yöntemlerdir.
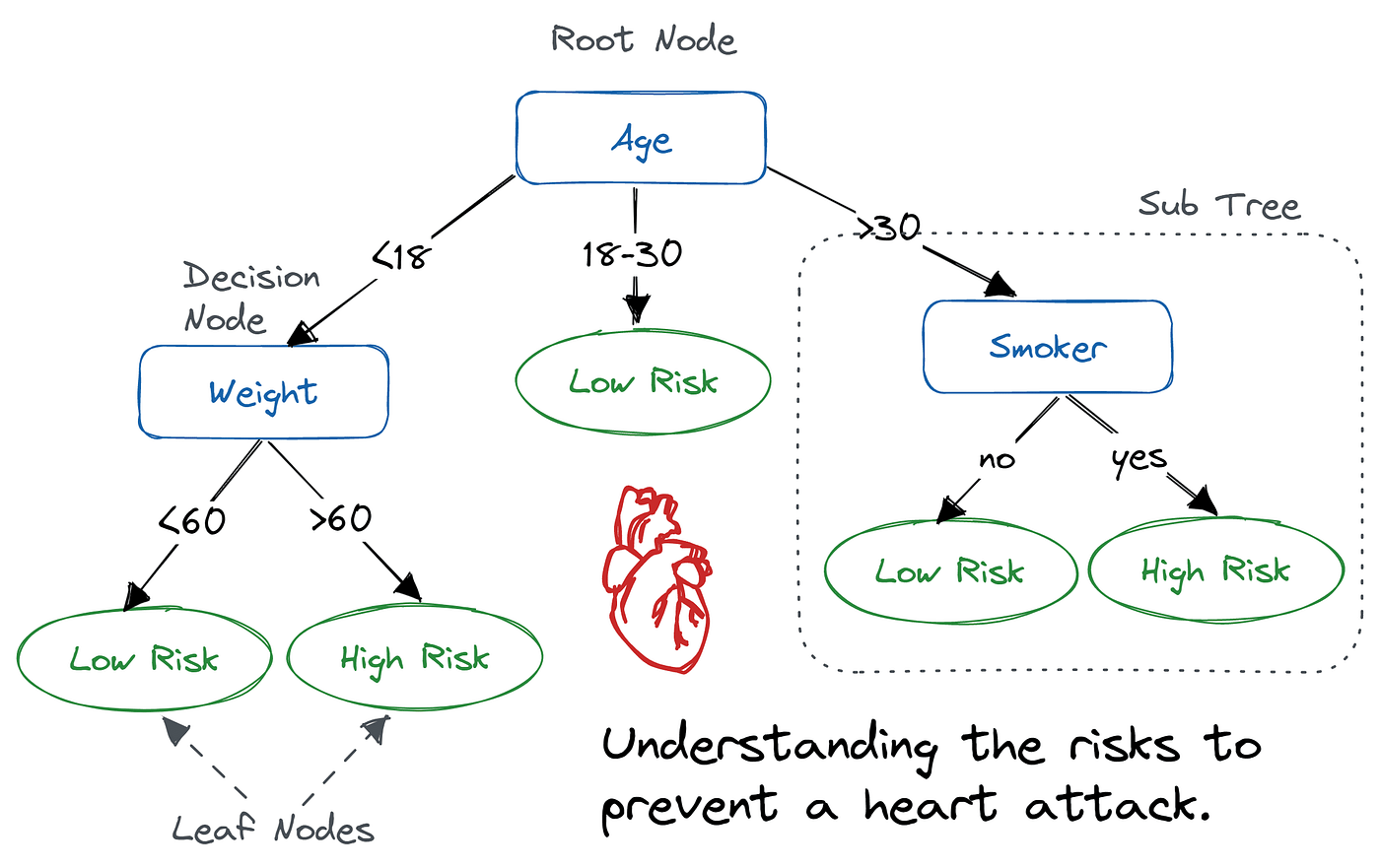
CAPTION Karar Ağaçları 5
Rastgele Orman (Random Forest)
Rastgele ormanlar, bir ensemble learning yöntemi olan karar ağaçlarının bir türüdür. Birden fazla karar ağacını bir araya getirerek daha güçlü ve hassas bir model oluştururlar. Her bir ağaç, rastgele seçilen özelliklerden oluşturulur ve bağımsız olarak eğitilir. Bu, her bir ağacın farklı bir özellik alt kümesine dayalı olarak öğrenme yeteneğine sahip olmasını sağlar.
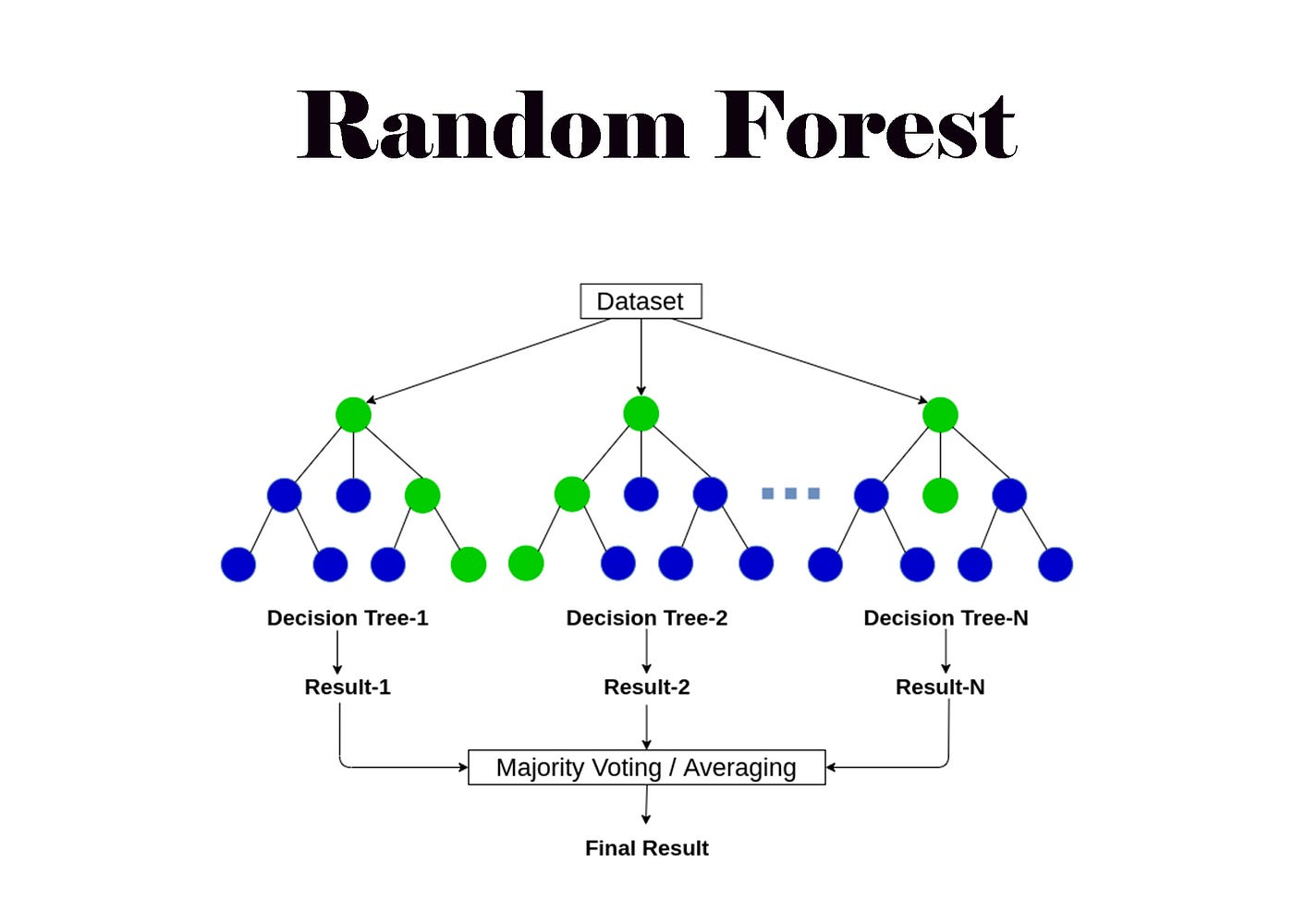
CAPTION Rastgele Orman 6
Destek Vektör Makineleri (Support Vector Machines)
Kısaca SVM, hem sınıflandırma hem de regresyon problemleri için kullanılan güçlü bir makine öğrenme algoritmasıdır. SVM, veri noktalarını sınıflandırma veya regresyon hedeflerini ayırmak için bir hiperdüzlem veya karar sınırı oluşturarak çalışır.
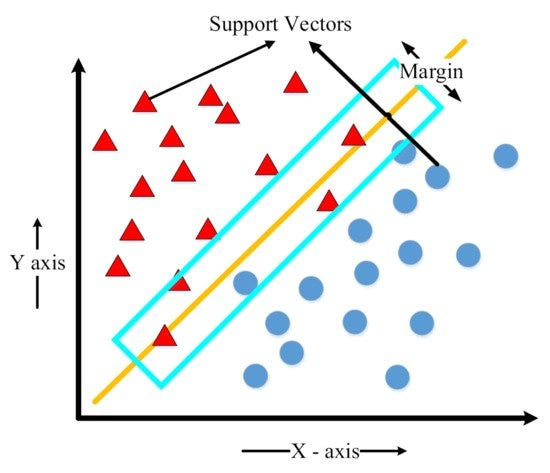
CAPTION Destek Vektör Makineleri 7
Naive Bayes
Naive Bayes, sınıflandırma problemleri için kullanılan bir makine öğrenme algoritmasıdır. Bu algoritma, Bayes teoreminin temelini oluşturur ve bağımsızlık varsayımı yaparak basit ve etkili bir şekilde çalışır.
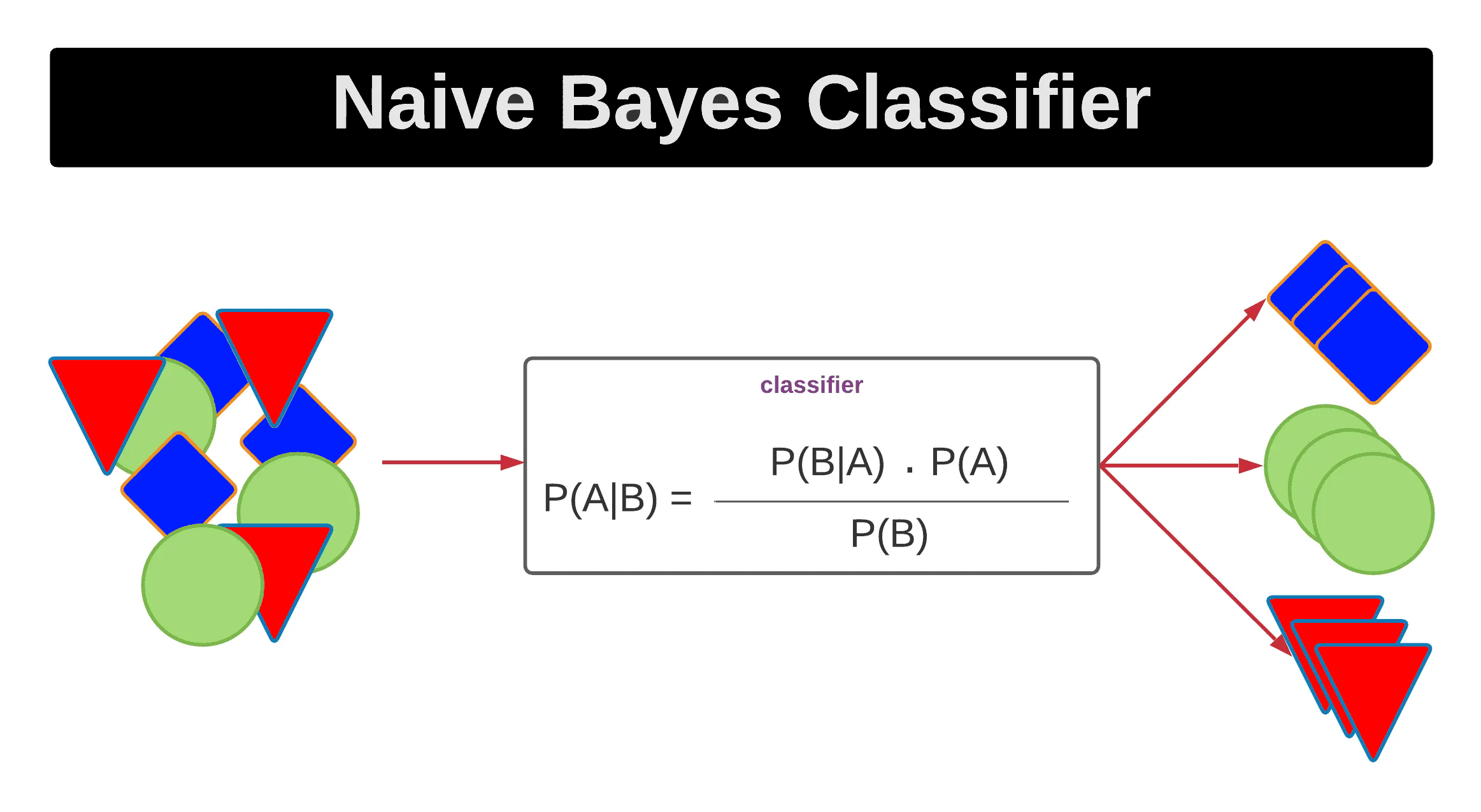
CAPTION Naive Bayes 8
K-En Yakın Komşu (K-Nearest Neighbors)
KNN algoritması sınıflandırma ve regresyon problemlerinde kullanılan bir makine öğrenme algoritmasıdır. Bu algoritma, bir veri noktasını sınıflandırmak veya bir değer tahmin etmek için en yakın komşuların çoğunluğuna dayanır.
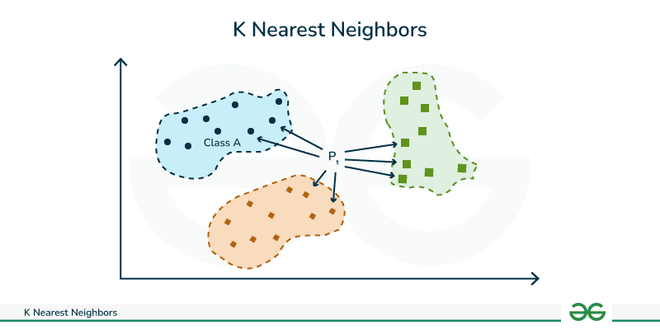
CAPTION K-En Yakın Komşu 9
Gradient Boosting
Gradient Boosting Algoritmaları, karmaşık tahmin modelleri oluşturmak için kullanılan güçlü bir makine öğrenme tekniğidir. Bu algoritmalar, zayıf tahmin modellerini bir araya getirerek güçlü bir tahmin modeli oluştururlar. Gradient boosting, ağırlıklı olarak sınıflandırma ve regresyon problemleri için kullanılır ve genellikle yüksek doğruluk sağlar. Gradient boosting algoritmalarının en yaygın kullanılanları arasında Gradient Boosted Trees (GBT) ve XGBoost bulunur.
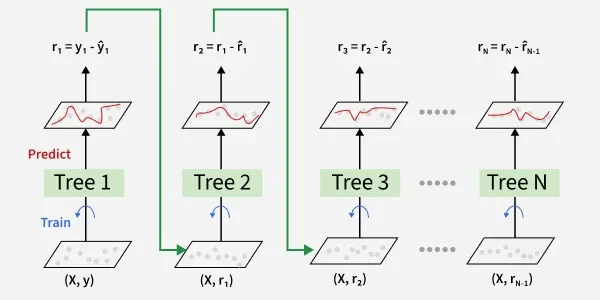
CAPTION Gradient Boosting 10
Gözetimsiz Öğrenme
Etiketlenmemiş veri kümeleri üzerinde yapılan bir makine öğrenimi yaklaşımıdır. Bu yaklaşımda, veri kümesindeki yapıyı anlamak, gizli desenleri keşfetmek ve veri noktaları arasındaki ilişkileri belirlemek amaçlanır. Genellikle veri keşfi ve veri ön işlemede kullanılır. Bu bir kümeleme yöntemi ile, verilerin içsel özelliklerine benzer gruplara ayırmayı içeren bir işlemdir. Ayrıca boyuz azaltma algoritmalarında anlamlı bilgiyi korurken, giriş değişkenlerinin veya özllik sayısını azatmak için kullanılır.
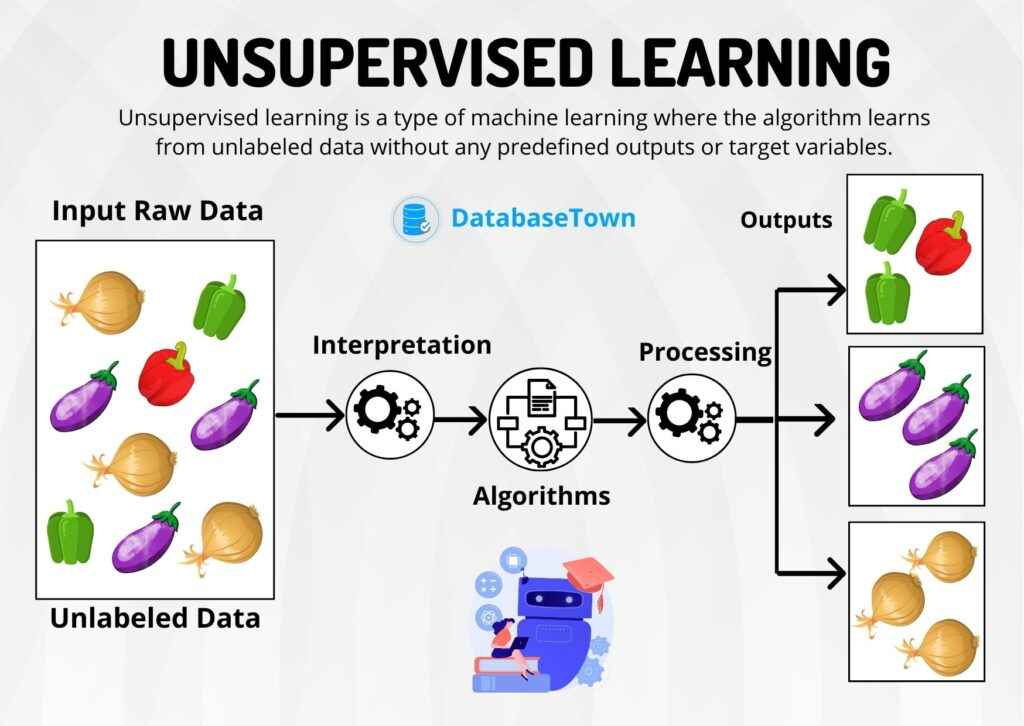
CAPTION Gözetimsiz Öğrenme 11
Burada K-Means, DBSCAN (Görüntülü uygulamalarda), gibi kümeleme yapan ve PCA (Temel Bileşen Analizi), T-SNE gibi de boyult azaltmada kullanılan algoritmalar bulunmaktadır.
Pekiştirmeli Öğrenme
Ortamla etkileşime geçerek bellirli bir görevi gerçekleştirmeyi öğrenmesini sağlayan bir öğrenme türüdür. Bir ajan ile ortamda belirli bir hedefi başarmak için ne tür eylemler yapması gerektiği öğretilir. Oyun yapay zekası, robotik, otomasyon gibi karar alma sistemlerinde gözükmektedir.
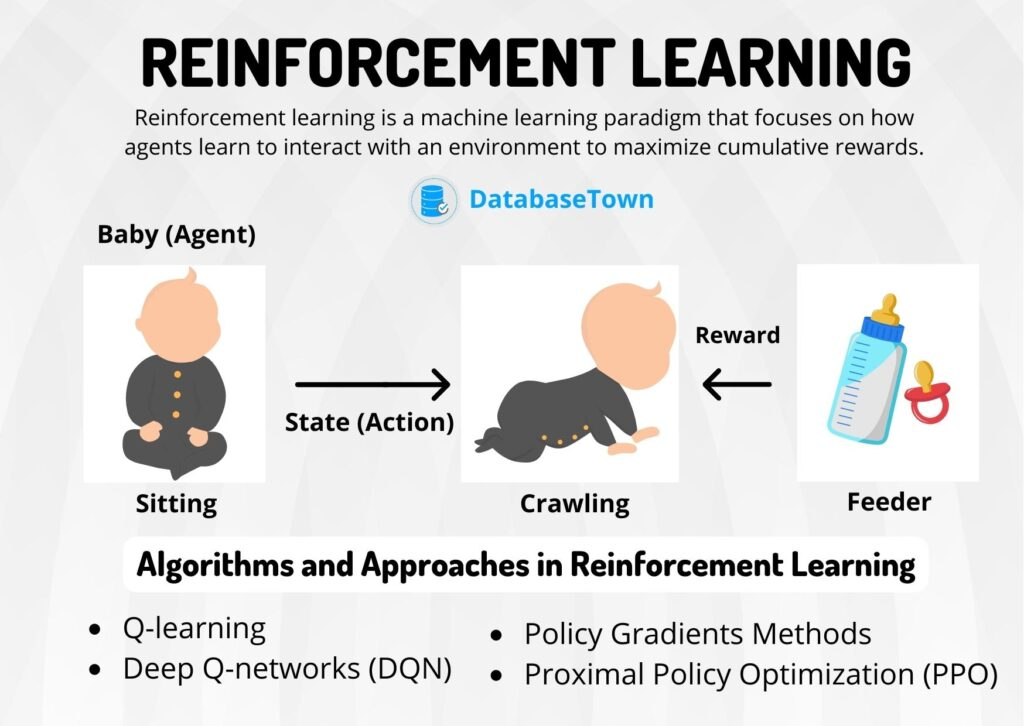
CAPTION Pekiştirmeli Öğrenme 12
Aslında görsel çok iyi bir açıklama sağlamakta. Pekiştirmeli öğrenmeyi bir çocuğun çevresini inceleyerek öğrenmesine bezetebiliriz.
Alt alanlarında;
- Model Tabanlı PÖ
- Model Tabanlı Olmayan PÖ
- Dğer Tabanlı PÖ
- Politika Tabanlı PÖ
Gibi seçenekler mevcuttur. Ayrıca derin öğrenme tarafında da bulunan farklı alt dalları bulunmaktadır.
Makine Öğrenmi Süreci
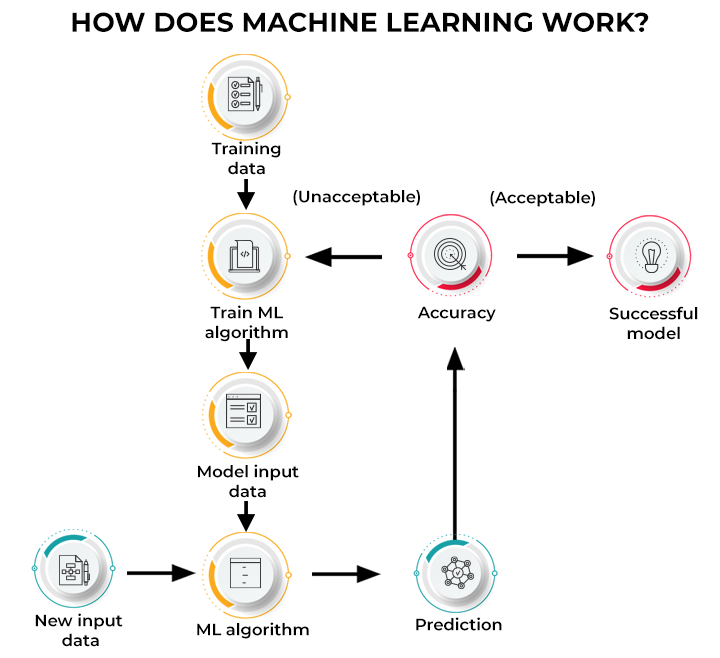
CAPTION Pekiştirmeli Öğrenme 13
Görsel üzerinden gidecek olursak, ilk açalamada veri toplama, dizenleme ve ön işleme süreci vardır. Sonrasında veriler doğrultusnda modelin seçilmesi ve eğitilmesi olacaktır. Sonrasında da sonuçlar değerlendirilir. Farklı bir veri seti ile testedilir ve değerlendirmeler alınır. Başarısız olursa başa dönerek yeniden model seçimi yapılır. Başarılı olursa da kabul edilir.
Araçlar
- TensorFlow
- Keras
- Scikit-learn
- Caffe2
- Apache Spark MLlib
- OpenNN
- Amazon SageManager
Modeller, algoritmalar, veri önişleme algoritmaları vb. birçok yapıyı barındıran farklı araçları listeledik.
Model Seçimi
- Problem anlaşılmalı.
- Başarı kriterleri tanımlanmalı.
- Veri gereksinimleri anlama.
- Veri gereksinimleri belirleme.
- Model eğitimi için veri toplama.
- Veri önişleme yapılmalı.
- Modelin özellikleri belirlenir.
Bu adımlar sonrası model eğitilir.
-
ResearchGate. Görsel Kaynağı ↩
-
DatabaseTown. Görsel Kaynağı ↩
-
GeeksForGeeks. Görsel Kaynağı ↩
-
Medium. Görsel Kaynağı ↩
-
Medium. Görsel Kaynağı ↩
-
Medium. Görsel Kaynağı ↩
-
Medium. Görsel Kaynağı ↩
-
ML Archive. Görsel Kaynağı ↩
-
GeeksForGeeks. Görsel Kaynağı ↩
-
GeeksForGeeks. Görsel Kaynağı ↩
-
DatabaseTown. Görsel Kaynağı ↩
-
DatabaseTown. Görsel Kaynağı ↩
-
Spiceworks. Görsel Kaynağı ↩